Problem Definition
Problem 1:
Part 1 requires tracking a predefined object on a video cam feed from a previously selected template image. The image needs to have a bounding box drawn around the object itself once found.
Part 2 requires being able to select between multiple different hand shapes. We chose to recognize the different hand shapes for rock paper scissors.
Method and Implementation
Give a concise description of the implemented method. For example, you might describe the motivation of current idea, the algorithmic steps or any formulation used in current method.
Part 1: The method was as follows:
Part 2: The method was as follows:
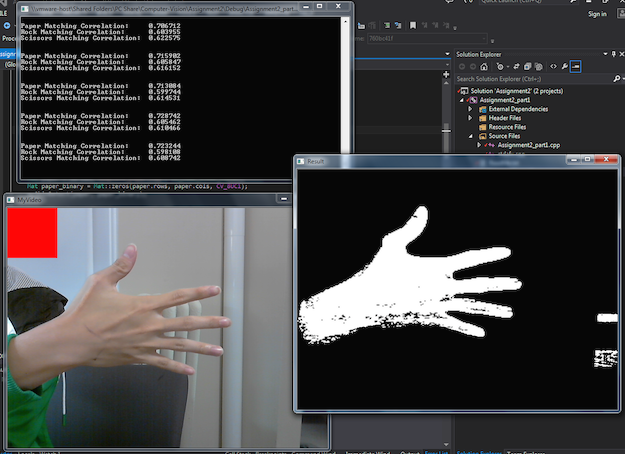
The way the template matching algorithm works is by taking the source image and scaling it down to some equal or smaller size. Then, then template image (in our case an rgb image of the source object) slides over every possible area of the resized source video feed image and a differencing is done to check for how much it matches, done in absolute value. The output is then a 1-channel image of how well correlated it is, and the better the correlation the brighter the pixel.
Experiments
Detection rate and accuracy:
Running Time:
Results
List your experimental results. Provide examples of input images and output images. If relevant, you may provide images showing any intermediate steps
Trials for Part 1
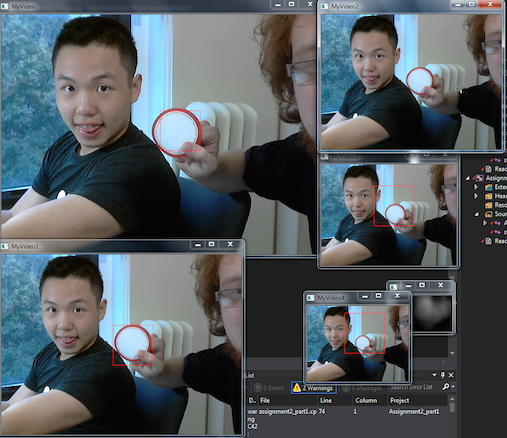
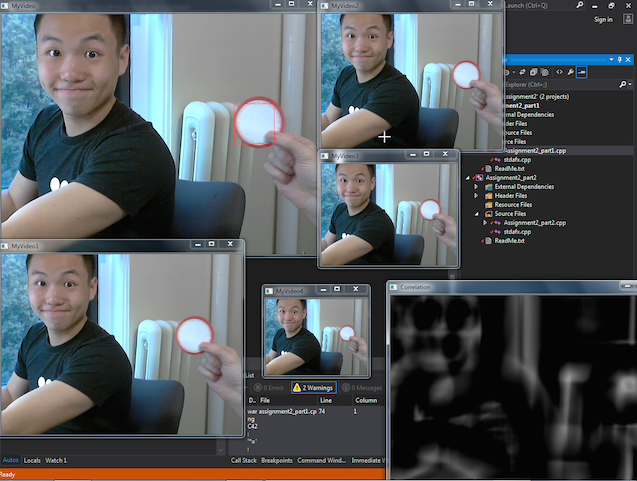
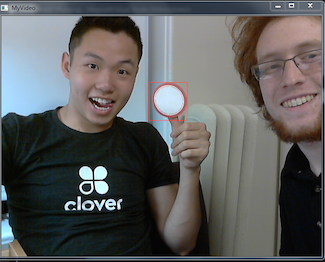

Trials for Part 1
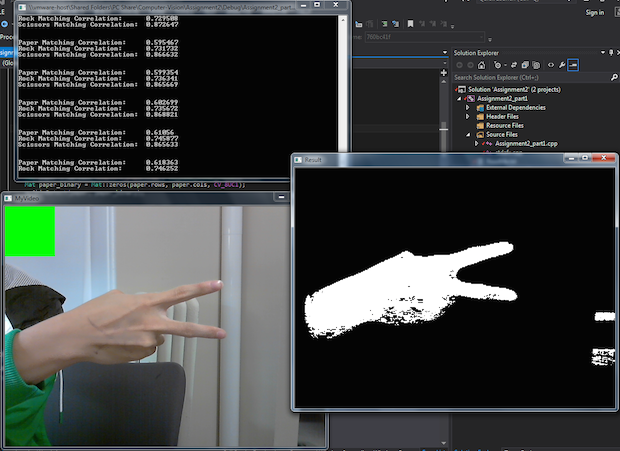
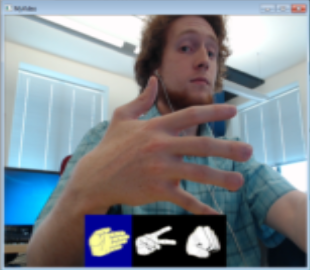
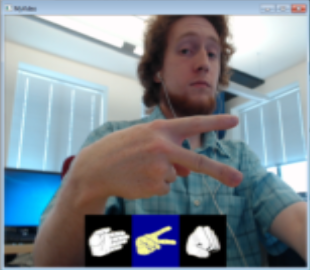
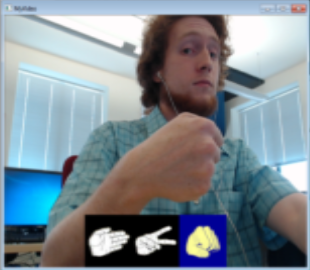
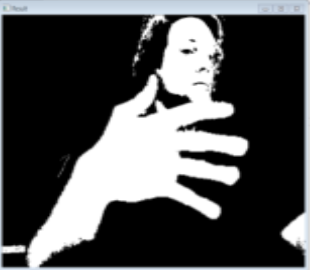
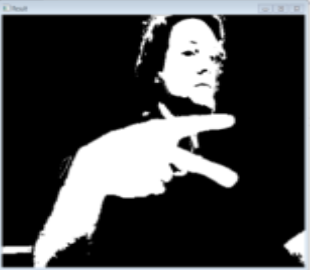
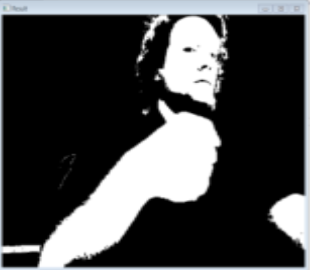
Confusion Matrix (Part 2) | ||||
| - | Paper (actual) | Scissors (actual) | Rock (actual) | No Shape (actual) |
| Paper (Detected) | 15 | 3 | 0 | 0 |
| Scissors (Detected) | 4 | 13 | 1 | 3 |
| Rock (Detected) | 1 | 4 | 19 | 0 |
| No Shape (Detected) | 0 | 0 | 0 | 17 |
The above confusion matrix shows 20 tests of putting a hand shape on or off screen with an intended shape, but with some intentional variations off of the exactly same pose. That is, I would intentionally put my hand in front of the screen with a paper symbol 20x, and see how many times it recognized it was the correct shape. In this case, it correctly recognized it 15 times, confusing it for something else 5 times.
Discussion
Discuss your method and results:
- Part 1: Running at 702 ms/frame, this is clearly quite slow. We tried to optimise it such that we would scale the image down as opposed to scaling the template up (which would take a lot more processing time for no additional useful data), but even still, it is quite slow. We did notice it worked reasonably well for 1 level of a template, but we wanted to make it even more robust with the pyramid of 5 levels. It could easily be scaled back to only implement 3 or even just 2 levels of the pyramid to run faster. That aside, the tracking of the object tis quite strong. Naturally one additional down side is the type of usable template. Using the template method, we did not have an easy way (certainly now with the already slow processing time). One further limitation of this result is the accuracy of the bounding box, since it is primarily based in reference on the track size used. It is not always going to be completely accurate, and to improve on that in the future we would need to use a different method to isolate the object first (and draw bounding box), and then run the template matching. The unfortunate thing about this is it almost defeats the main usefulness of template matching,
- Part 2: This part worked quite well, given that we didn't do any pyramid scheming and that it functioned quite nicely even given blurry or fast moving hand shapes to detect the intended shape. It was very good at determining when there was a hand or not on screen, but we noticed that the rock shape was often confused with the scissors shape. To cope with this, we added the re-weighting scheme where if there was a high correlation between both scissors and rock at the same time, scissors would be slightly preferred. This re-weighting schemed worked quite well and allowed us to easily tweak the sensitivity of each shape independent of the others, or as a whole.
- For both parts, the key drawback is the lack of variation accepted by the template matching algorithm. For instance, if you rotate the scissors at all off from horizontal, it quickly gets interpreted as either paper, or (more likely) as a rock, since it isn't matching the fingers in the template which stay horizontal. Likewise, if you use your other hand (ie mirror direction) it would not detect the paper and scissors properly since the template is directed/asymmetric. With regards to part one, it is true we intentionally chose a round object so we would not have to compensate for rotational discrepancies.
- Additionally to rotation, variance in lighting is not very well handle by part one since a binary image is not used for tracking. However, for part two it does quite well through the skin detection in varying light levels (skin detection thresholds did need to be slightly modified)
- More work that could be done, without completely changing the approach, would be to reduce the number of pyramid steps in part 1 to two or three to get enough of a performance boost to do other things. Such other things include doing a better bounding box search, based on the local area of where the bes matching template is found.
- I also want to acknowledge that there was more of an attempt put into making the GUI more sophisticated. As can be found in the source files /animation/ folder, it was intended for each time a new gesture was recognized a little animation would play bringing up the according one. While we were temporarily able to get the animation play using either imreads or videocap like the webcam, it was too apparent that the frame rate of the system was far too slow to warrant even a short animation of 4-6 frames, so it was removed from the final code. Huge speed improvements would be necessary to do any further visual processing on top of the current core.
Conclusions
My primary conclusion is that template matching works well, but it quickly becomes quite slow and is not adaptable easily for different orientations and other transformations. In the future, I would probably only use any form of template matching if necessary (such as with faces it would likely be harder to do segmentation and additional logic in comparison to the same accuracy track as a
Credits and Bibliography
citations: Only outside code used was for skin detection from the lab session, and the template matching algorithm built into openCV.
Both parts 1 and 2 were developed with Timothy Chong.