With MCprep version 3.0.3, users will be able to report errors automatically to the developer. This page explains what that means and how such reports are used.
How are these reported errors used?
While it is great that MCprep users leverage the issue tracker, not everyone takes the time to create GitHub accounts and submit new issues. Hence, this feature makes it easier than ever to give direct feedback right as something goes wrong. When aggregated, this helps indicate where the code has bugs and even on which platforms.

A sample popup as seen inside blender – “How is the used” links to this page
What about privacy?
Firstly, these error reports are entirely anonymous. To prove this fact, take a look at example raw data sorted in the database (made a little bit more friendly for human-reading):
- ID# – MCprep install id. This is an auto-generated ID at the time of first installing, to be able to group error reports from the same user without actually being able to trace back to that user in any way.
- (2, 79, 0) – The running blender version
- Error report – the raw error message, with filepaths redacted to e.g. addon_path/__init__.py
- User message – whatever the user entered into the comment box before hitting OK and sending the report
- Windows/Mac (Darwin)/Linux – The running operating system and version number
- “June 7, 2018 5:47 AM” – The timestamp (converted from seconds) when the report is received, using the database’s timezone and clock, not the user’s (knowledge of user’s timezone would be partially identifiable information)
- (3.0.3) – The installed MCprep version

Database screenshot
As should be evident, no personally identifiable information is included. Even filepaths to the addon’s files are automatically masked out by MCprep before the report is sent to the database online. Want more information? Be sure to check out the MCprep Privacy Policy here
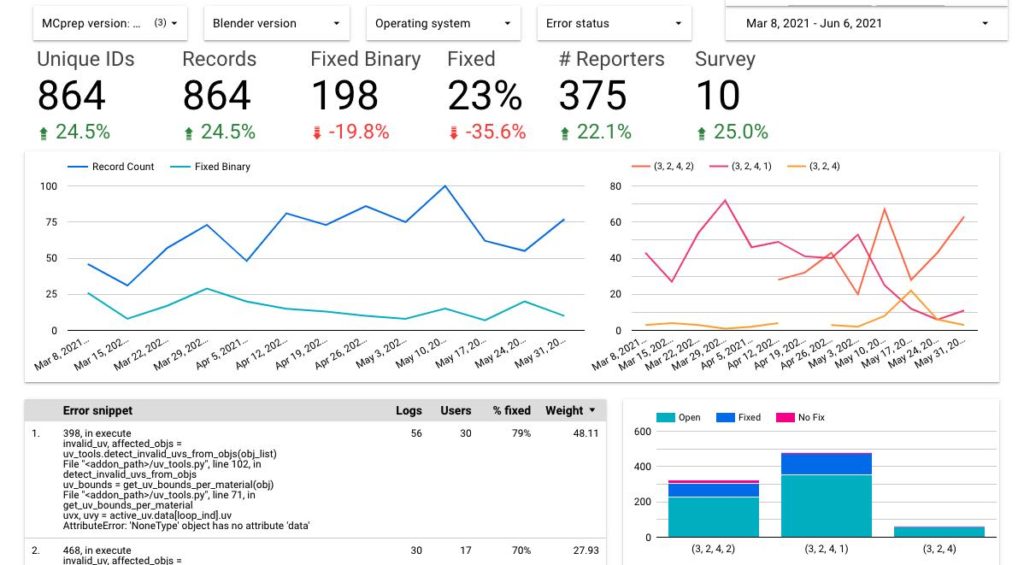
Analyzing reporting errors
Individual error reports aren’t always that helpful. The power of this built in reporting mechanism is that it allows the developer to cluster similar errors together. The custom (private) reporting pipeline ultimately creates a view like the one below, which helps with identifying the top bugs to fix. It also helps for seeing the increase or decrease of bug reports over time, and confirming specific bugs don’t crop up after being supposedly fixed. While there may never be a point where there are zero reports for a period of time, the goal is to minimize it as much as possible!